
Make Your Own Twitter in C++ with Redis
Just like a wise person said, Don’t like twitter? Design your own 😃 Believe me, it is quite interesting to code a working skeleton of the popular messaging platform on your desktop. You can use the back-end API services to send tweets, follow users and see your time-line. In this journey, you will have chance to work with several technologies such as Redis, the defacto in-memory key-value datastore and C++Rest server.
Project Repository
To check the code, navigate to the GitHub page of BabyBird project and keep reading here for more details.
Description of Backend Services
In this design, I will focus on the basic functionality, no user registration, no trend topic selection or no friend recommendation. My aim is to have the basics work on desktop. It can also be accessed remotely though. I used cURL but other tools such as Postman will also work.
Tweet Writer API
There is only one basic function of this endpoint, which is sending messages to the server. In REST world, this is pretty straightforward. We will use POST request and include the message content in JSON payload.
curl -X POST --data '{"userId": 1, "content": "Hello World!"}' localhost:8080/api/v1/tweet
On successful request, the back-end will respond HTTP 204: Created code.
Timeline View API
After populating the server with some tweets of several users, one can request timeline to view the most recent messages of followed users as well as self messages. For this simple project, we can use tweetId as the ordering criteria, since it is an increasing unique number. Make the following request for userId=1.
curl -v --request GET localhost:8080/api/v1/timeline/1
Follow API
When creating the timeline, we check the followed users and get top-K tweets. We can create this x-follows-y relation using HTTP PUT request and remove it using HTTP DELETE verb to unfollow.
curl -v --request PUT localhost:8080/api/v1/follow/1/2
curl -v --request DELETE localhost:8080/api/v1/follow/1/2
The first userId in the URL is follower and the second one is followee. Messages from the followee will be included in follower’s timeline.
About the Components
Redis Database
Redis is an in-memory distributed database which is very suitable for many use-cases. Lots of popular highly available internet services use Redis as cache to offload the main database such as RDBMS. Since Redis supports several data types, it is also suitable to be used as the main database rather than a cache only. It can be used as a NoSQL key-value DB as in this project. If you don’t have your own setup, create a Redis Cloud account with free plan in seconds so that you can use it for this project.
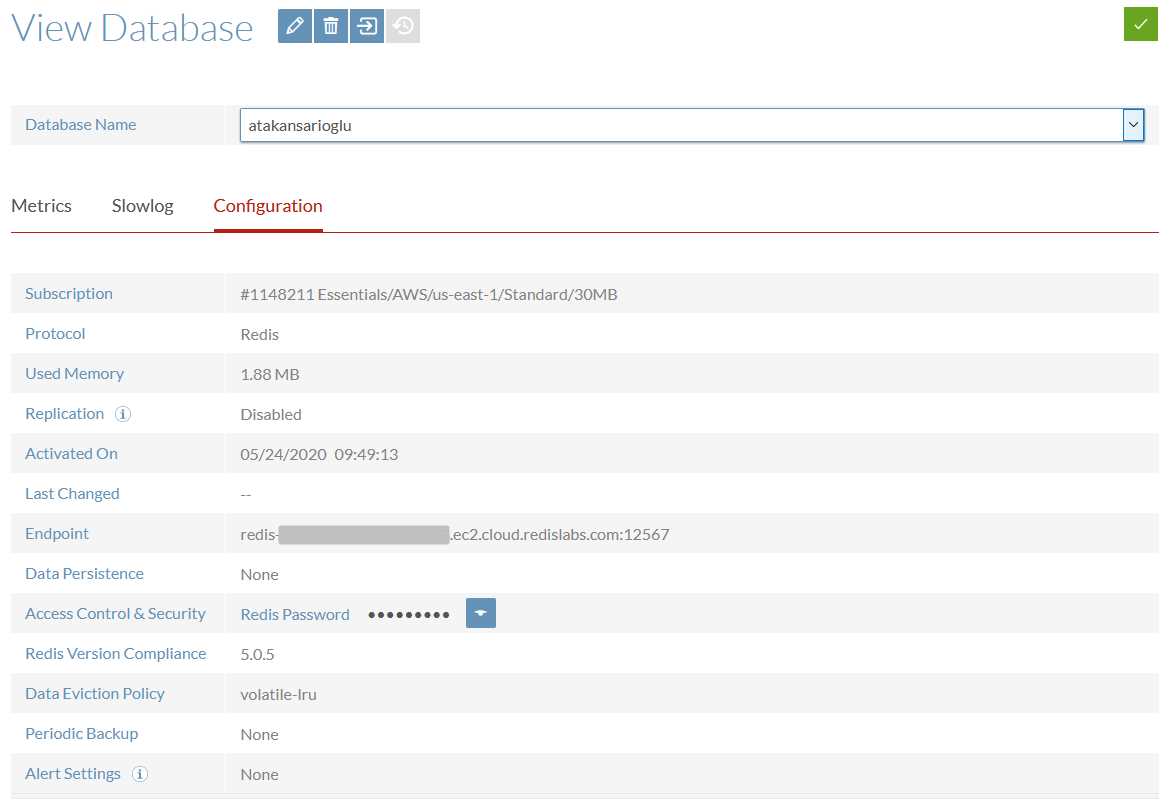
Note that the database in my free plan has no replicas but in a real solution, you can benefit the replication of Redis so that your data is copied to multiple clusters and no commodity server is a single point of failure.
Cpp Redis Library
I use cpp_redis library to connect to Redis server. It uses asynchronous calls of C++11 and returns std::future objects to access the response data. See the instructions here for setup.
Cpp Rest Server
For the REST back-end, I used C++Rest SDK. It is provides easy-to-use, asynchronous structure with out-of-the-box JSON parser. Refer to this post for further details.
C++ Twitter Design
I used Visual Studio Code and worked on Ubuntu 20.04 LTS for development and the project uses CMake. Please check the readme for the instructions on compilation.
UML Class Diagram
The following class diagram helps to understand the main components in the object-oriented design.
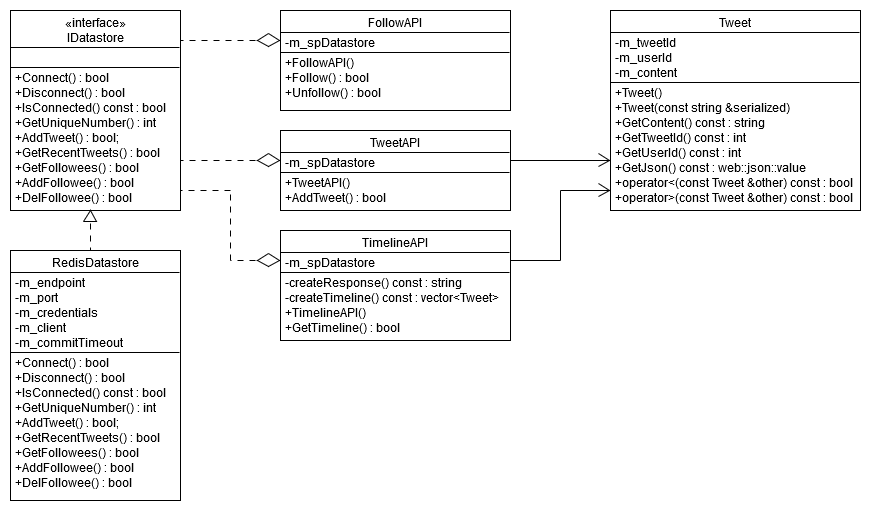
Tweet Object
As you can see in the UML above, Tweet class has the message content, userId of the owner and a unique id number that also represents the creation time (i.e. greater the tweetId means more recent tweet). It uses JSON to create a serializable representation of the object. De-serialization is possible via the converting constructor that parses the input string as JSON to get the field values.
Datastore Interface and Redis Connector
For simple decoupling, IDatastore interface is implemented so that the datastore can be replaced on-the-fly. Here the responsibility of this interface might seem bulky and that is correct. In a real project, it is better to create another layer of abstraction, with the only task of maintaining database read/write operations, such as IDatastoreConnector. This way the business logic such as creating and listing tweets can be segregated into the API classes.
Tweet API
This API gets the datastore object with dependency injection in its constructor. In AddTweet(...) method, it gets a unique number from the datastore, creates a Tweet object, serializes it and sends to Redis. Of course, this two-step operation is bad-practice and this can be fixed by using real timestamp instead of increasing id numbers. On the other hand, this operation is vulnerable to race condition since another tweet can get a smaller id but sent to the database later. Those situations need to be handled carefully.
Tweets are stored in LIST objects on Redis and each user has its own LIST named tweets:userId. To add new tweet, LPUSH followed by LTRIM operations are committed. Since Redis is not a document-store by default, the tweets are serialized as JSON before pushing. Number of stored tweets are limited to 10 currently and this is maintained by LTRIM. Finally, LRANGE is used to retrieve the stored tweets.
Follow API
All users can follow any number of users and the followee list is stored as SET on Redis named followees:userId for each user. To create new followee, SADD and to delete SREM is used. To obtain all users who are followed by a user, SMEMBERS is used.
Timeline API
This is the most critical part of the design and lots of effort is needed to make it faster since the system is read-heavy by around 1000:1 ratio. In this project I preferred a traditional approach.
First, we need the list of users that are followed by the current user. Second we need to pull all tweets that belong to the followed users and the user’s own tweets. Since we store 10 tweets for each user, timeline will have 10 most recent tweets.
After getting all the tweets, there are several approaches to create the timeline. One can sort all the tweets in a single list and get the first 10 but this is O(NlogN) with quick-sort or merge-sort. Here the choice could be merge-sort due to its distributed nature. On the other hand, we are not interested in sorting everything and finding only the top-10 suffice.
This can be done by using Min-Heap with O(NlogK) time complexity where K is the timeline size. Space complexity is O(K) only which is better than O(N) space required by merge-sort. In C++ we can use minimum priority queue and push(...) a tweet into PQ only if it is more recent than the least-recent (minimum) object on the top(...) , after pop(...) . The below code snippet represents this approach.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Minimum Priority Queue std::priority_queue<tweetref_t, std::deque<tweetref_t>, std::greater<Tweet>> minPq; // Check all the tweets. for (size_t i = 0; i < tweets.size(); ++i) { // Push tweets to the MinPQ only if they are more recent than the oldest tweet in MinPQ. if (minPq.size() < maxTweets || !minPq.empty() && minPq.top().get() < tweets[i]) { minPq.push(std::ref(tweets[i])); } // Pop the least recent if the size exceeds. if (minPq.size() > maxTweets) { minPq.pop(); } } |
Note that maxTweets=10 in this setting.
Backend API
The back-end is created in main.cpp and it uses Rest API server (notice that this is experimental). It starts listening on the given port of localhost. The following HTTP requests are served.
- GET – Timeline API
- POST – Tweet API
- PUT and DEL – Follow API
The dispatchers can be moved into separate file for keeping the main tidy, in the first refactor phase.
Summary
This is a proof-of-concept project only since many building blocks, error-handling parts and tests are missing. It needs several refactoring to become a good project before it is ready to be put onto server. Use it for educational purposes and have fun 😏